About the solution
Media2Cloud BETA is designed to demonstrate a serverless ingest framework that can quickly setup a baseline ingest workflow for placing video assets and associated metadata under management control of an AWS customer. The solution will setup the core building blocks that are common in a ingest strategy:
- Establish a storage policy that manages master materials as well as proxies generated by the ingest process.
- Provide a unique identifier (UUID) for each master video asset.
- Calculate and provide a MD5 checksum.
- Perform a technical metadata extract against the master video asset.
- Build standardized proxies for use in a media asset management solution.
- Run the proxies through the media analysis solution.
- Provide a serverless dashboard that allows a developer to setup and monitor the ingest process.
Diagram (below) illustrates the functional aspect of Media2Cloud solution
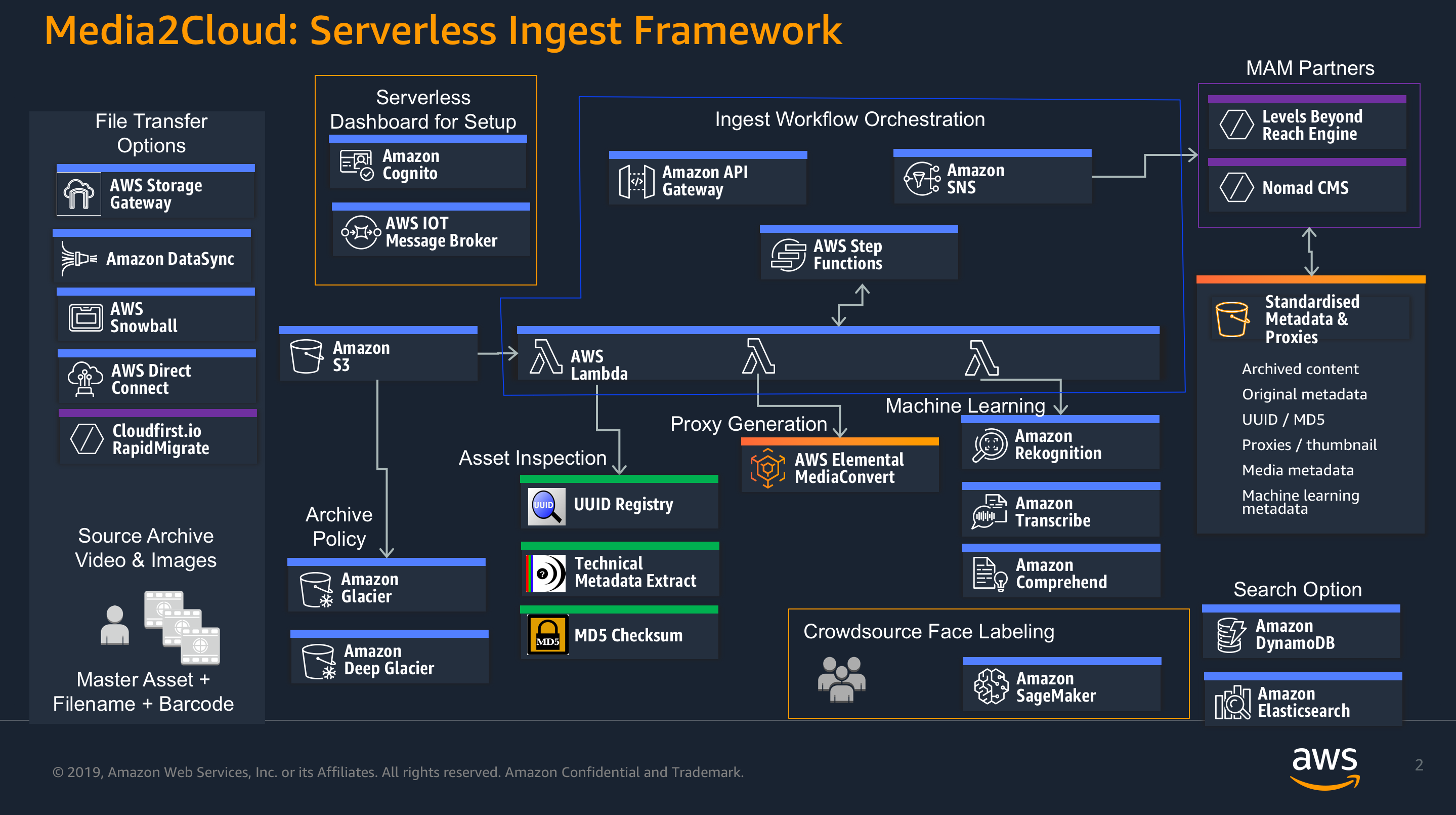
Media2Cloud solution uses various AWS managed services included but not limited to the followings:
- Amazon Cognito service to manage user signin/signout/access control to the ingest dashboard.
- Amazon Glacier and Amazon S3 to archive the uploaded assets and to store generated information.
- AWS Internet of Things (Iot) to provide async messaging for connected web clients through MQTT pub/sub service.
- Amazon Rekognition, Amazon Translate, Amazon Comprehend services to extract AI/ML metadata from the uploaded assets.
- Amazon DynamoDB to store asset information.
- AWS Step Functions service to manage the ingest and metadata workflows.
- Amazon Elasticsearch Service to provide search capability.
- AWS Elemental MediaConvert to create streamable proxy of the uploaded asset.
- Amazon API Gateway and Amazon SNS services for communications.
- AWS Lambda Function to power all serverless logics.
Last but not least, Media2Cloud solution supports the following regions:
- us-east-1 (N. Virginia)
- us-east-2 (Ohio)
- us-west-2 (Oregon)
- eu-west-1 (Ireland)
- ap-southeast-1 (Singapore)
#Team AWS Media & Ententainment

User first needs to authenticate himself with Amazon Cognito User Pool. He/She would then be granted a temporary credential to access certain AWS resources. Note that you could also authenticate against your own AD with Amazon Cognito Federate Identity services through SAML2.0 or OpenID Connect (ODIC).
The solution uses Amazon IoT Core's message broker to receive asynchronized messages from the backend services. Amazon IoT utilizes MQTT over websocket to keep the client(s) connected. Alternatively, you could also use Amazon SNS or AWS AppSync (GraphQL) service.
Once the user is signed in, the webapp will scan the asset table and to display the relevant information.
Uploading a file using webapp includes the following steps
- Generate a UUID for the asset
- Calculate MD5 checksum of the entire file
- Use S3 multipart upload API to upload the file where:
- MD5 checksum of the entire file is stored in 'x-amz-metada-md5chk' metadata field
- Multipart upload also performs MD5 checksum of each part before the part is uploaded
- Part size is set to 8MB
The solution supports an use case where you directly upload a file to the S3 bucket without the webapp. There are differences:
- 'x-amx-metadata-md5chk' metadata field won't be generated. It is up to you to calculate the MD5 checksum and set the metadata field.
- If 'x-amz-metadata-md5chk' metadata field is missing, the solution assumes '0000'
- Similarly, UUID will also be set to '0000'
Once the file landed on S3, it triggers a lambda function (omitted in the digram) which starts 'ingest state machine' (Amazon Step Functions)
In this state, the Lambda Function runs Mediainfo command to gather the technical metadata of the video file. Couple interesting notes:
- The lambda function doesn't download the entire video file.
- Mediainfo fetches just enough data to parse the file.
- Even if you have 40GB file, it only requires a few KB or MB to parse the video file.
- The solution also uses signed URL of the S3 object
In this state, the Lambda Function prepares a job template and submit a job to AWS Elemental MediaConvert to create a proxy version. If a video file is MXF that contains multiple channels, the lambda function downmixes all channels into stereo so that you don't lose any channel information.
MediaConvert takes the source file and transcodes it into 960x540, AVC@1800Kbps MP4 proxy file. It also does frame capture to provide the thumbnail rendered on the webapp.
Once the proxy file is generated, the ingest workflow is almost done. The very last state is to send a notification to a SNS topic. Tip: if you have downstream processes that would like to start when our ingest is completed, subscribe to the SNS topic. When you receive notification from us, start your downstream workflows as needed.
The solution uses 3 different tables, Configuration, Asset, MediaInfo where
- Configuration table stores settings (created dynamically during the CloudFormation Stack creation) that are needed to run the webapp.
- Asset table stores information of an asset such as MD5, UUID, pointers to proxy, metadata, and etc.
- Mediainfo table stores technical media data of the asset.
Throughout the ingest process, the solution sends messages to Iot message broker. The webapp (connected to Iot) gets notified.
When the proxy is created, a state lambda function will call putObjectTagging API to set 'IngestCompleted' to true. The Glacier bucket is configured to have a Lifecycle Policy to transition object to Glacier storage based on this 'IngestCompleted' tag.
Once the ingest process is completed, the webapp enables a feature to create metadata. Upon request, the webapp sends the request to API Gateway to start the metadata state machine.
The API Gateway exposes a simple api endpoint (POST method) for starting the state machine. The endpoint is protected by AWS_IAM which means the request is signed with AWS SigV4. For more details, see Signature Version 4 Signing Process
The Media2Cloud solution was designed to take advantage of the existing, published AWS solution, Media Analsysis Solution. Thus, instead of building a different pipeline for AI/ML service, the solution leverages Media Analysis Solution by invoking its analysis state machine. In this state, the solution simply runs the media-analysis-solution state machine and periodically check the exceution status.
Media Analysis solution workflow
Media Analysis Solution ingests metadata generated by Rekognition, Transcribe, and Comprehend services to Elasticsearch engine. Our solution uses the Elasticsearch engine to provide search capability.
In this state, the media-analysis-state-machine has completed, the solution simply collects all the AI/ML results and prepare the next state.
In this state, the solution generates the subtitle (.vtt) file from the transcription. In addition to that, the solution indeed generates other WebVTT tracks out of the AI/ML metadata such as Labels, Celebrities, Faces. The HTML5 player in this solution simply renders the metadata as if it is webvtt tracks. Each of the clickable buttons under the Preview's carousel view loads a webvtt track.
Similar to Step 10.
Similar to Step 11.
Similar to Step 9
As mentioned earlier, the search capability is provided by Elasticsearch engine. Search any term generated by AI/ML services, Elasticsearch engine will return a list of assets that contain the term.